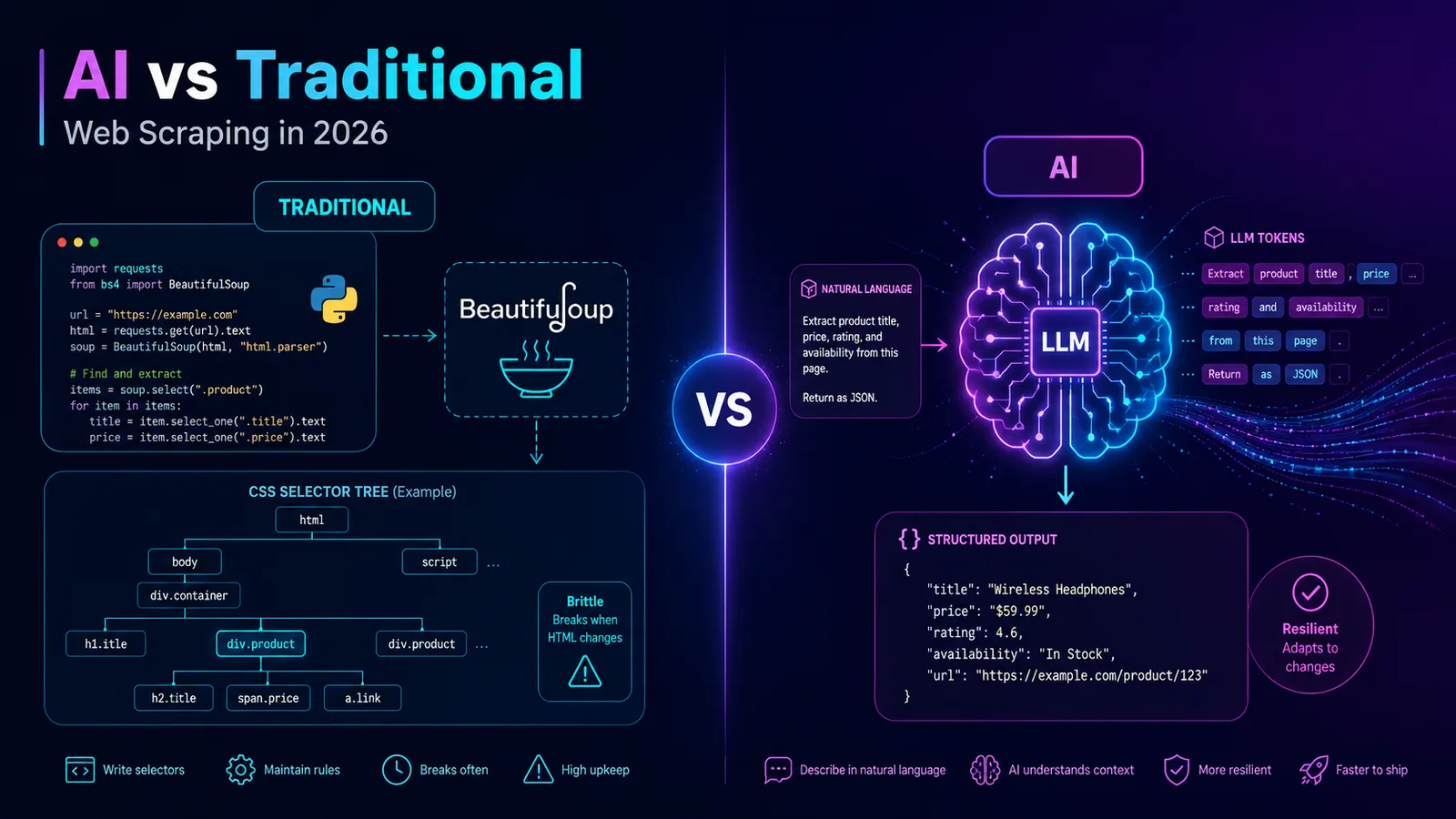
In 2024, scraping a product page meant 30 minutes of Python + BeautifulSoup: open DevTools, hunt for the right CSS selector, write a parser, hope the site doesn't ship a redesign next Tuesday. In 2026, you can paste the same HTML into GPT-4 with a one-line schema and get clean JSON back in under 5 seconds. No selectors. No parser. Just words.
So is traditional scraping dead? Not even close. It's just no longer the default. The interesting question now isn't which one is better — it's which one fits the job in front of you. This guide walks through both stacks honestly, with real numbers, and a hybrid pattern that most teams I know quietly converged on this year.
What we mean by traditional scraping
Traditional scraping is the boring, battle-tested stack. You fetch HTML, you parse a DOM, you pull values out with selectors. The toolset hasn't changed much in a decade and that's a feature, not a bug.
- BeautifulSoup + requests (Python) — the duct tape of the internet. Forgiving parser, easy to debug, perfect for static HTML.
- lxml — same idea, faster, stricter. Good when you're parsing millions of pages and every millisecond matters.
- Scrapy — the framework. Built-in crawling, retries, pipelines, throttling. If you're scraping a whole site, start here.
- Cheerio (Node.js) — jQuery-style API for server-side HTML. Great fit for JS-heavy stacks.
- Playwright / Puppeteer — headless browsers for JS-rendered pages. Slower and heavier, but they see what users see.
Where it shines: deterministic output, near-zero per-page cost, blazing fast (milliseconds), and it scales to millions of pages on a single VPS. Where it hurts: every site needs its own custom code, CSS selectors are brittle, and a single redesign can silently break your pipeline at 3am.
What AI scraping actually means in 2026
AI scraping is conceptually simple: fetch HTML (or a screenshot), hand it to an LLM with a target schema, get structured JSON back. The model does the parsing for you.
- ScrapeGraphAI — open-source Python library, point it at a URL with a Pydantic-style schema and an LLM key, done.
- Firecrawl — turns any URL into clean markdown or JSON, good at handling JS and pagination.
- Jina Reader API — free-tier endpoint that converts a page into LLM-friendly markdown.
- Browse.ai with LLM extraction — recorder-style tool with an LLM layer for messy fields.
- Plain GPT-4 / Claude with Vision — paste a screenshot and a schema, skip the HTML entirely. Useful when the DOM is a hostile mess.
Where it shines: zero per-site code, survives redesigns (the model just re-reads the page), and handles semantic extraction — "pull every spec from this product description" — that would take a regex army to do by hand. Where it hurts: cost (cents to dollars per page), latency (1–10 seconds vs milliseconds), occasional hallucinations on edge cases, and non-determinism that makes debugging genuinely annoying.
Side-by-side comparison
Numbers are rough orders of magnitude based on real 2026 pricing — your mileage will vary by site complexity and provider.
| Dimension | Traditional | AI | Hybrid |
|---|---|---|---|
| Cost per 1,000 pages | ~$0.05 | $2–$10 | $0.20–$0.50 |
| Time to first result | 30 min – 2 hr (writing code) | 30 seconds (write a schema) | 1–2 hr |
| Maintenance burden | High — breaks on redesign | Low — model adapts | Medium |
| Handles redesigns | No | Yes | Mostly |
| Handles anti-bot | Same as AI (proxies + browser stack do the work) | Same as traditional | Same |
| Best for | High volume, stable sites | Prototyping, messy pages | Production at scale |
When traditional scraping wins
If any of these describe your job, write the parser:
- High volume — millions of pages a month. At that scale, $300 in LLM tokens becomes $300,000 fast.
- Stable, structured sites — Wikipedia, government open-data portals, sitemaps, RSS feeds. The DOM hasn't moved in years and won't.
- Real-time pipelines — sub-second latency budgets. An LLM round-trip alone is longer than your SLA.
- You control the parser — when correctness must be auditable and reproducible, you want code, not a probability distribution.
When AI scraping wins
- Prototyping and one-off research — you need 200 rows by Friday, not a maintainable codebase.
- Sites that redesign frequently — marketplaces, news sites, anything DTC. Selectors there have a half-life of weeks.
- Semi-structured content — PDFs rendered as HTML, news articles, long product descriptions where the data lives in prose, not in
<span class="price">. - You can't easily target with selectors — DOMs hand-built by frontend teams who hate scrapers, or sites where the same field has 12 different layouts.
The hybrid pattern (what most teams ship in 2026)
Here's the dirty secret: most production scrapers in 2026 aren't pure-traditional or pure-AI. They're hybrid. Use the cheap, deterministic stack for the 80% of fields that are stable and structured, and fall back to an LLM for the 20% that's messy.
Concrete example — e-commerce product pages:
- Use Playwright + BeautifulSoup to grab title, price, SKU, image URLs, and breadcrumbs. These have stable selectors and you scrape them at full speed.
- Take the long, free-form product description and pipe it to GPT-4o-mini with a schema like
{material, dimensions, weight, care_instructions}. The LLM extracts spec data the marketing team wrote in prose.
You pay LLM cost on maybe 500 tokens per page instead of 8,000. That's the difference between $300 and $30 per 100k pages.
Three real-world examples
1. Scraping all SEC 10-K filings (2M+ documents)
Winner: traditional. The structure is regular, the volume is enormous, and the EDGAR system has been stable for 20+ years. Scrapy + lxml will outrun any LLM stack by three orders of magnitude on cost.
2. Pulling structured data from 50 random Shopify stores
Winner: AI. Every store has a different theme. Writing 50 parsers is a week of work that breaks weekly. ScrapeGraphAI or Firecrawl with a shared schema gets you 90% accuracy in an afternoon.
3. Building a real-time price tracker for 10k products on 5 retailers
Winner: hybrid. Write deterministic parsers per retailer (5 of them, manageable) for price + stock status. Use an LLM monthly to re-scrape full descriptions and catch new spec fields. Cost stays low, freshness stays high.
Cost reality check: 100k product pages
Back-of-envelope math, assuming average page is 8k tokens of HTML, GPT-4o-mini at ~$0.15 / 1M input tokens, and a small VPS at ~$5/month.
- BeautifulSoup + Scrapy on a $5 VPS: ~$5 total. Time investment: 1–2 days writing and testing the parser.
- Pure GPT-4o on full HTML: ~$300 in tokens. Time investment: 1 hour. Add latency overhead and rate limits.
- Hybrid (traditional fields + LLM for descriptions only): ~$30 in tokens. Time investment: ~1 day. Best ROI for production work.
Scale that to 10M pages a month and the math becomes brutal — pure-AI scraping at that volume is $30k/mo in tokens alone. Which is exactly why hybrid is the dominant production pattern.
What about anti-bot?
Here's something worth saying loudly: Cloudflare, Akamai, and PerimeterX do not care whether you're using GPT-4 or BeautifulSoup. They block based on TLS fingerprints, IP reputation, browser entropy, and behavioral signals — none of which change based on what's parsing the response after it arrives.
Both stacks need the same anti-bot toolkit:
- Residential or mobile proxies (Bright Data, Smartproxy, Oxylabs) for IP diversity.
- Stealth browser configs — Playwright with
playwright-stealth, or undetected-chromedriver, to defeat fingerprint checks. - Rate limiting and human-like delays — being polite is also being undetected.
- Respect
robots.txtand ToS — not because it's legally binding everywhere, but because ignoring it is how scrapers get sued. Public data is mostly fair game in the US after hiQ v. LinkedIn; it's stickier in the EU under GDPR. When in doubt, talk to a lawyer, not Reddit.
Try a no-code scraper to start
If you're not a developer (or you just want to see what's on a page before committing to a Scrapy project), our free Web Scraper is a low-stakes way to start. Paste a URL, pick the fields you want, get JSON, CSV, or Markdown back.
Honest disclosure: it's static-HTML only — no JS rendering, no headless browser. That puts it firmly in the traditional camp. It won't work on heavy SPAs that render everything client-side, but it's perfect for blogs, docs, government sites, and most of the static web. First scrape is free without signup; signed-in users get 20/day.
Picking the right tool
The honest answer in 2026 is that it's not AI versus traditional — it's a portfolio. Quick framework for picking:
- Volume > 1M pages/month or sub-second latency? Traditional. Always.
- One-off, prototype, or messy semi-structured data? AI. Don't waste a day on selectors.
- Production scraper that needs to last 12+ months? Hybrid. Deterministic for stable fields, LLM for the messy edges.
Pick the tool that matches the job, not the one that's trending on Hacker News this week.
FAQ
Is AI scraping cheaper than writing code?
Cheaper to start, more expensive to run. If you're scraping fewer than ~10k pages, AI usually wins on total cost (your time is worth more than the tokens). Past 100k pages a month, traditional or hybrid wins by 10–100x.
Do I need to know Python to scrape with AI?
For prototyping, no — Firecrawl, Browse.ai, and similar tools are no-code. For anything you want to run on a schedule with retries, error handling, and storage, you'll still want at least basic Python or Node. The LLM removes the parser, not the engineering.
Will AI scraping scale to millions of pages?
Technically yes, financially probably not. At a million pages a day on full-HTML LLM extraction, you're looking at five-figure monthly token bills. The right move is hybrid: extract stable fields with code, route only the ambiguous prose to an LLM.
Is web scraping legal?
Scraping publicly accessible data is broadly legal in the US (see hiQ Labs v. LinkedIn). Stricter rules apply under GDPR in the EU, and most sites' ToS prohibit it regardless of legality. Don't scrape behind logins you don't own, don't republish copyrighted content verbatim, respect robots.txt, and rate-limit politely. None of this changes based on whether your parser is regex or GPT-4.